
먼저 이번 행사는 아래와 같은 순서로 진행 되었습니다.
1. 환영 인사 및 키노트
2. 모듈 1 - Google Cloud Platform 소개
3. 모듈 2 - Google Cloud Platform 시작하기
4. 모듈 3 - 클라우드 환경에서의 가상 머신
5. 모듈 4 - 클라우드 스토리지
6. 모듈 5 - 클라우드 컨테이너 서비스
7. 모듈 6 - 클라우드 애플리케이션
8. 모듈 7 - 클라우드 환경에서의 개발, 배포 그리고 모니터링
9. 모듈 8 - 클라우드 빅데이터 및 머신러닝
아젠다만 봐도 엄청 빡빡한 일정이라는 것을 보실 수 있는데요. 오전 10시부터 오후 5시까지 꽉꽉 채워서 진행 되었습니다. 목적 자체가 클라우드에 대한 개념정리 시간이다보니 방대한 내용을 다루되, 너무 깊이있게 들어가지 않아서 저같은 비전문가도 충분히 이해할 수 있었는데요. 그럼 지금부터 정리 시작 해 보겠습니다!
환영 인사 및 키노트 / 윤석만 상무

Google은 전세계 10억명 이상이 사용하는 클라우드 제품을 제공하고 있으며 이 10억명의 개인 사용자들의 데이터를 기반으로 기업고객에게도 제공하고 있는 서비스가 바로 Google Cloud Platform 입니다. 10억명이라니 정말 엄청난 숫자네요. 아마 단일회사 서비스로 가장 많은 사용자를 확보한 것이 Google이 아닐까 합니다.

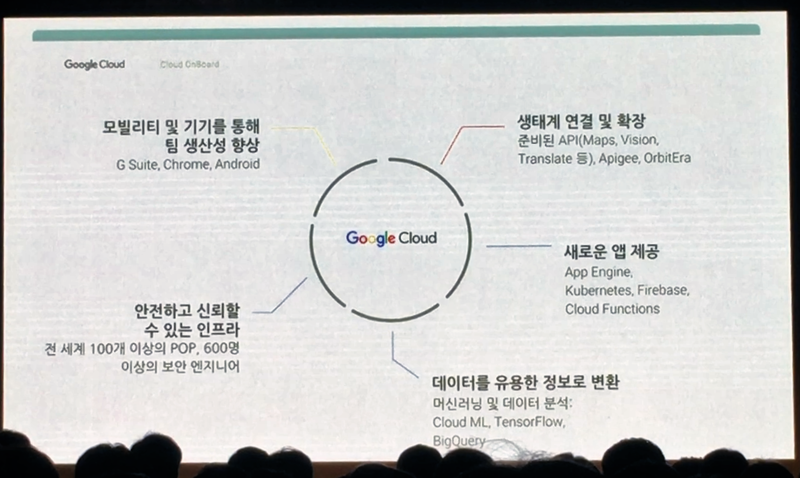
Google은 일찍이 Google Cloud Platform의 전신인 App Engine을 출시했으나 시장이 준비가 되지 않은 상태에서 너무 앞서갔던 것이라고 판단 했습니다. 하지만 이 App Engine을 기초로 하여 위 장표에서 보시는 것 처럼 많은 서비스들이 나왔는데요. Google이 개인사용자들을에게 제공하는 검색, 메일, 지도, 유튜브, 모바일 등등 이런 서비스를 유지하기 위해 보유한 IT인프라는 전세계에서 가장 거대하다고 볼 수 있고, 이 엄청난 IT인프라를 일반 기업 뿐만 아니라 개인들도 자유롭게 사용할 수 있는 것이 바로 Google Cloud Platform인 것입니다. 위 장표에서 언급 된 다양한 서비스들은 이후 이어질 모듈에서 다루겠습니다.
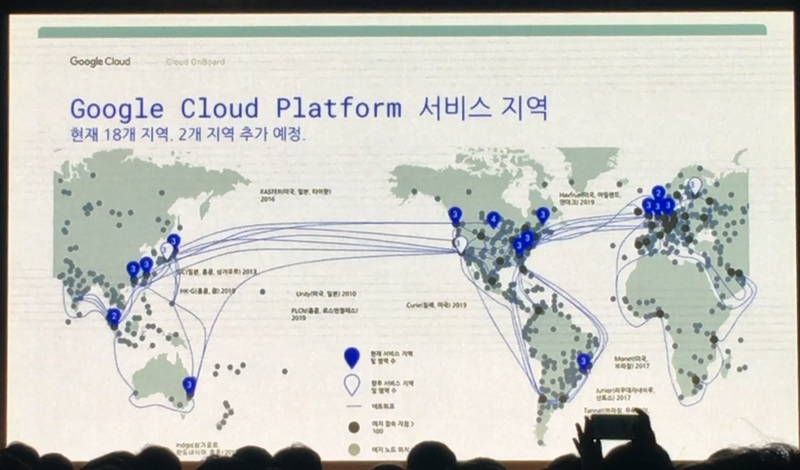
아쉽게도 아직 Google Cloud Platform 리젼은 한국에 없습니다. 가장 가까운 곳이 일본과 싱가폴인데요. 경쟁사(AWS, Azure)에 비해 국내 사용자들에게는 단점으로 생각될 수 있으나 미국이나 유럽 쪽 리젼을 사용하지 않는 이상 크게 체감하긴 어려울 수 있습니다. 더 중요한 것은 코딩이니까요. 거기에 앞단의 웹서비스 쪽은 국내 리젼이 있는 클라우드를 이용하고 뒷단의 데이터 처리를 위한 서비스는 Google Cloud Platform를 이용하는 등 멀티클라우드로 간다면 크게 문제될 것은 아닙니다만 그래도 살짝 아쉬운 것은 사실입니다.
어쨌든 Google Cloud Platform은 10억명이 사용하는 서비스를 통해 전세계 인터넷 트래픽의 25%에서 많게는 40%까지 처리하고 있는 네트워크 인프라를 제공합니다. 전세계에서 가장 큰 규모의 전용 광케이블을 가지고 있고 이 방대한 네트워크를 Software Defined Network로 운영하고 있습니다. 가장 진보된 기술의 네트워크 인프라를 통해 서비스를 운영하려면 Google Cloud Platform을 이용하면 되는 것이죠. 발표자의 멘트를 빌리자면 '거인의 어깨에 올라서서 멀리 내다볼 수 있는 통찰력을 제공하는 것이 Google Cloud' 입니다.
모듈 1 Google Cloud Platform 소개 / 박기택 인스트럭터
이제 본격적인 오늘 세션의 시작입니다. 모듈 1부터 모듈 8까지 진행 되었는데요. 각 모듈 별 핵심 내용 위주로 정리 해 보겠습니다. 본 모듈은 모두 박기택 인스트럭터가 진행 했습니다. 이번 Google Cloud Onboard의 대상은 클라우드가 처음이거나 Google Cloud라고 하면 Google Drive가 떠오르시는 분 혹은 기술직군이 아닌 분들입니다. 그래서 내용 역시 개념에 대한 설명과 청중의 이해도를 높이는 쪽에 초점을 맞춰 진행 되었습니다. 그만큼 이미 클라우드 엔지니어로 활동하시는 분들께는 새로울 것이 없을 수 있으니 참고하시고 봐 주시면 좋을 것 같아요.
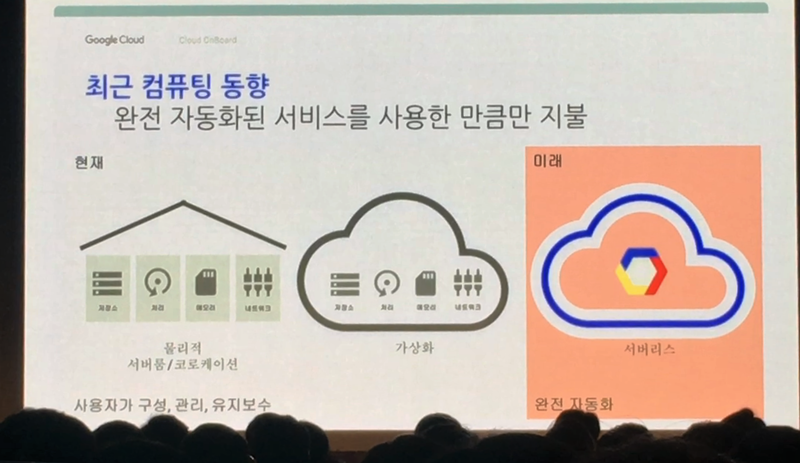
최근 컴퓨터 업계 동향은 완전 자동화된 서비스를 사용한 만큼만 지불하는 것입니다. 기존의 전통적인 방식은 보유한 인프라의 사용량이 충분하지 않기 때문에 비효율적이었죠. 이것을 해결하기 위해 나온 것이 바로 가상화 기술(Hypervisor)입니다. 하지만 가상화는 대용량의 데이터(페타바이트 이상의 빅데이터)를 분석할 때 HW 관리에 많은 투자가 필요합니다. 그래서 HW를 관리하지 않는 Serverless 환경을 추구하게 되었죠.(사용자 입장에서 더이상 서버 인프라를 어떻게 구축할 지 고민할 필요가 없어진 것입니다.) 따라서 이제 고객은 소스코드 개발이나 데이터 분석 등 보다 가치있는 일에 집중하고, 인프라 관리는 Google같은 클라우드 회사에 맡기는 것이 최근 동향이라고 할 수 있습니다.
즉, 과거 제조기업들은 인프라 투자 시 대충 감으로 따져서 투자 해 왔었습니다. 이후 수요와 공급에 따라 분석 후 의사결정을 내려 인프라에 투자하게 되었죠. 그런데 데이터의 중요성이 점점 증대되었습니다. 데이터의 양이 적을 경우 크게 문제가 되지 않았지만 이제는 데이터의 양이 너무나 많아져서 나의 온프레미스 시스템에서 더이상 분석이 불가능할 정도까지 많아져 버렸습니다. 그래서 Cloud를 이용해야 한다는 것입니다. 대기업이 아니라면 IT기술력이 아주 좋지 못할텐데요.(대기업의 뛰어난 인재들이 나와 설립한 스타트업은 예외입니다.) Google은 일반 기업들의 온프레미스 대비 10년 이상 앞선 기술력을 가지고 있다고 자부한다고 합니다. 이런 앞선 기술을 사용할 수 있는 혜택을 Google Cloud가 제공하고 있는 것입니다.
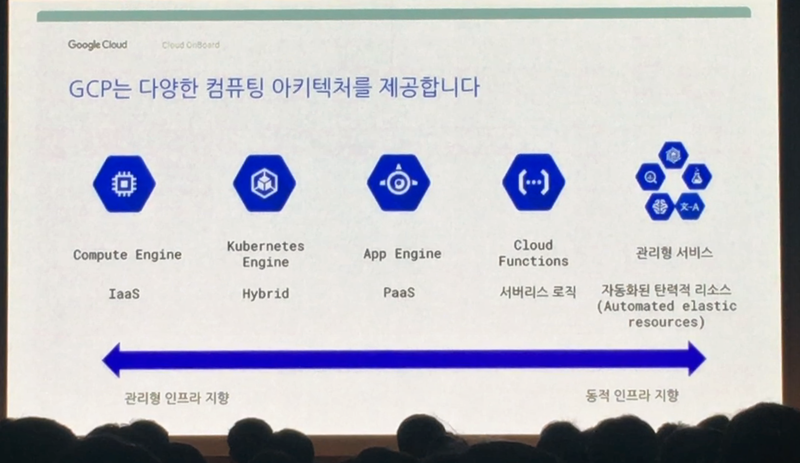
위와 같이 GCP(Google Cloud Platform)은 다양한 기술을 제공하고 있습니다. 각 영역별 내용에 대해서는 이후 모듈에서 자세히 다루도록 하겠습니다. Compute Engine부터 관리형 서비스까지, 하나의 애플리케이션을 개발하고 운영하기 위한 모든 것을 제공하고 있다고 보시면 되겠습니다.
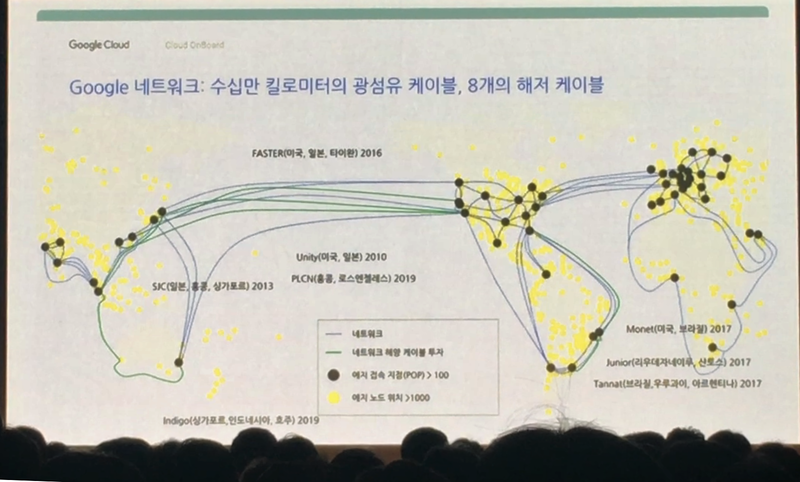
앞서 키노트 세션에서 잠깐 보여 드렸던 리젼은 3개 이상의 존이 모인 곳입니다. Google은 전세계의 리젼과 존을 직접 Google 전용 광케이블로 연결 했습니다. 위 장표처럼 직접 해저케이블도 깔았는데요. 이 해저케이블은 일본 기타큐슈의 OCC(Ocean Cable & Commnications)라는 회사에서 개발되었고 길이가 100gbps의 속도를 지원합니다.

가격 측면에서 볼 때 클라우드 서비스이기 때문에 온프레미스 대비 인프라 투자비용이 들지 않습니다. 또한 사용한 만큼 운영비용만 내면 됩니다. Sub-hour단위 증가분 결제라는 것은 초단위 까지 과금한다는 이야기 입니다. 내가 사용한 정확한 시간을 계산해서 그 시간만큼만 과금한다는 것이죠. 시간 단위로 끊는 것이 아니기 때문에 합리적인 비용을 지불할 수 있습니다. (과거 PC방에서 2시간 이용권 구매했다가 2시간 10분 사용하고 2시간 30분 혹은 3시간 비용을 지불했던 것에 비하면 매우 합리적이라 할 수 있겠습니다.) 하지만 현재 서비스 하고 있는 모든 클라우드 서비스들이 위 장표와 같은 과금체계를 가지고 있기 때문에 Google만의 장점이라고 보기는 어렵습니다.
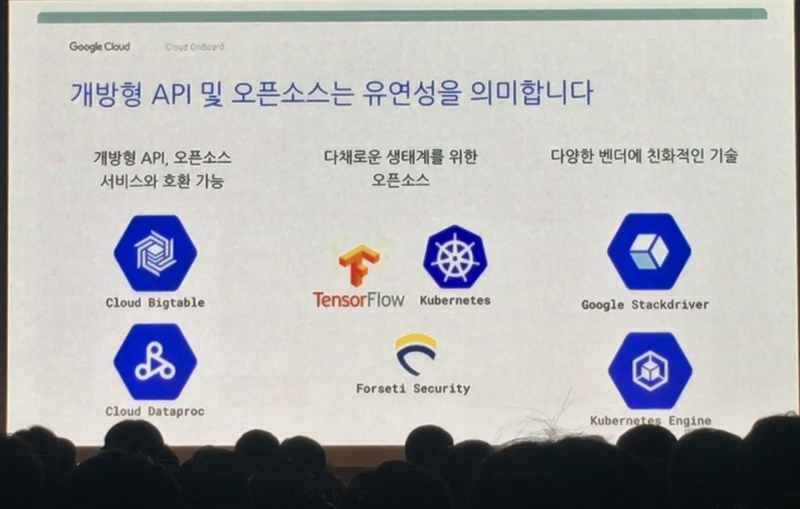
Google Cloud의 많은 기술들은 오픈소스로 공개되어 있습니다. 이는 최근 특정 벤더 서비스 의존도가 높을 경우 그 벤더에 귀속되는(Lockin) 것에 대한 두려움을 해소시킬 수 있는 장점이 될 수 있습니다. 단, 뛰어난 오픈소스 전문인력이 있다는 전제가 필요합니다.

보안에 있어서도 Google은 세계 최고 수준을 자랑합니다. 모든 HW는 별도로 Google 환경에 맞게 커스터마이징 되었고 데이터센터에도 내부 직원 중 극히 일부의 허가된 사람들만 다중보안체계를 통해 출입할 수 있습니다. 보안에 많은 투자를 하기 어려운 회사라면 오히려 Google같은 글로벌 기업의 Cloud를 이용하는 것이 더 안전할 수 있다는 이야기 입니다.
하지만 많은 기업들이 자신들의 중요한 데이터를 Cloud로 옮기는 것에 대해 두려움을 가지고 있습니다. 기업에서 중요하게 여기는 것은 무엇일까요? 사람, 돈, 데이터 3가지 일텐데요. 과거부터의 추세를 살펴보면, 처음에는 자신들이 직접 이 중요한 자산을 지켰습니다. 그러다가 은행같은 대신 보안을 철저히 해 주는 회사로 옮기기 시작했죠. 즉, 우리가 신뢰할 수 있는 보안이 뛰어난 곳에 기업의 자산을 옮기는 것이 추세입니다. 거기에 처음부터 모두 Cloud로 옮기지 않아도 됩니다. 일부만 옮겨서 경험을 해 보고 점진적으로 옮겨가면 되는 것입니다.
모듈 2 Google Cloud Platform 시작하기
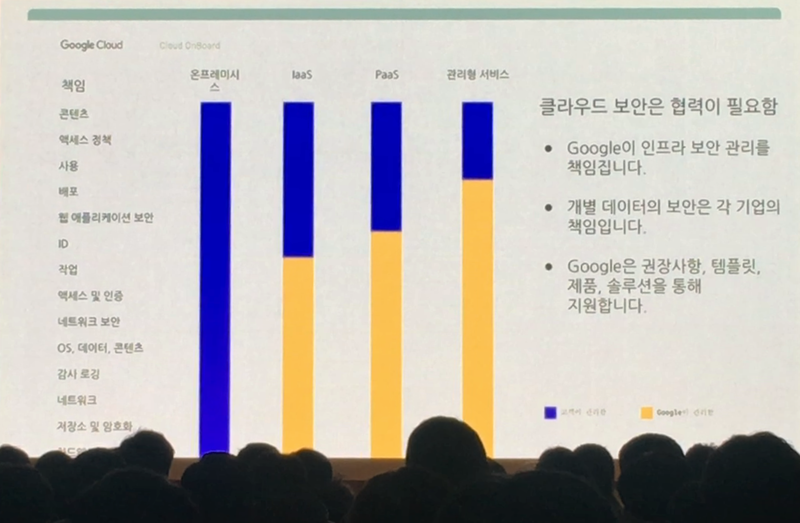
Google Cloud Platform을 시작하기에 앞서 다시 한번 보안이 서두에 나왔습니다. 클라우드 서비스를 이용함에 있어 가장 중요한 것이 보안이기 때문이죠. 기존 온프레미스 환경에서는 특정 서비스를 운영함에 있어서 HW부터 모든 단계에 있어 스스로 보안을 책임져야 합니다. 하지만 Google Cloud를 이용하게 되면 HW인프라 단의 보안은 Google이 알아서 책임집니다. 발표자에 따르면 Intel의 CPU보안이슈(기사 참고)를 Google에서 발견하여 Intel에 알려줬다고 합니다.
이렇게 Google은 HW 인프라 보안은 철저히 관리하고 있지만 클라우드 인프라 위에 서비스를 올리는 순간부터 그 서비스 데이터에 대한 보안은 개별 기업들이 관리해야 합니다. Google은 보안을 잘 지킬 수 있는 여러가지 기능을 제공하지만 이 기능을 사용해서 보안을 철저하게 강화하는 것은 기업들의 몫인 거죠. 가장 기본적인 것이 바로 권한 관리 입니다. 아무리 뛰어난 보안기능으로 중무장 했다 하더라도 모든 권한을 가지고 있는 어드민 계정이 관리가 제대로 안된다면 낭패이니까요. 적절한 사람에게 적절한 권한을 주는 것이 중요한 이유입니다.
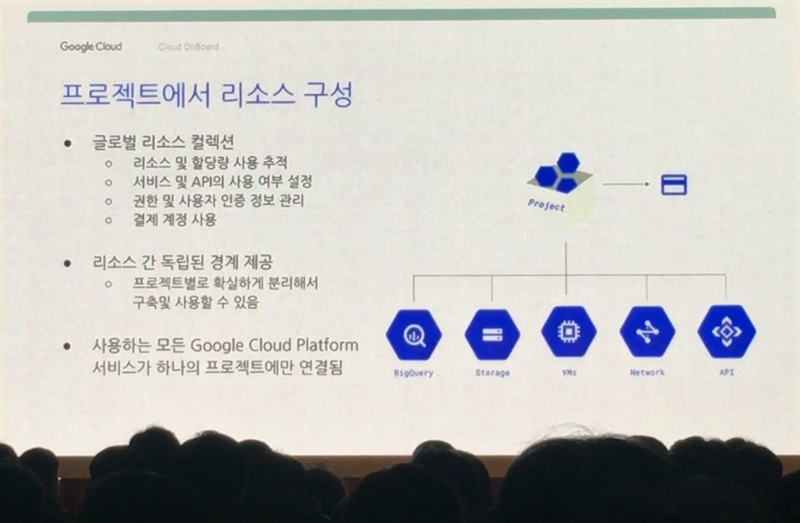
Google Cloud Platform은 프로젝트 단위로 관리 됩니다. 하나의 프로젝트에 각종 리소스(Google Cloud Platform에서 제공하는 각종 기술들)를 할당하여 활용하는 형태입니다. 용도 별로 프로젝트를 생성하여 관리해야 하는 것이죠.(매출 분석 프로젝트, 세일즈 기회 분석 프로젝트 등) 이 프로젝트들이 여러개가 모여 하나의 폴더를 이룹니다. 그리고 이 폴더들이 모여 하나의 조직을 이루는 구조입니다. 위에서부터 내려오면 조직 -> 폴더 -> 프로젝트 -> 리소스 인 것입니다. 아래 장표를 보시죠.
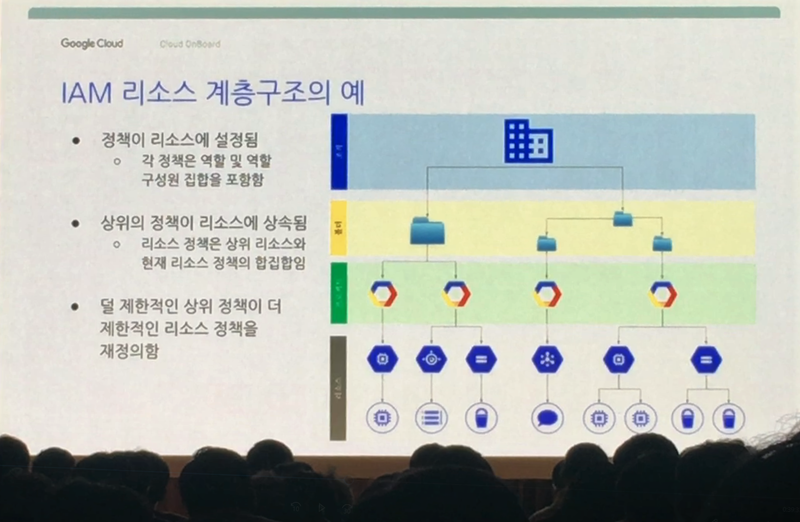
조직을 하나의 회사로 볼 때 폴더는 부서 정도로 볼 수 있겠습니다. 각 부서에서 진행하는 목적에 맞는 프로젝트가 있고, 그 프로젝트 하단에 프로젝트 수행을 위해 필요한 리소스가 놓여져 있습니다. 가령 개발 프로젝트를 생성하여 각종 리소스를 부여한 프로젝트가 있을 때 개발팀에게는 수정권한이 부여되지만 기획팀에게는 수정권한이 아닌 읽기권한 정도만 부여되어야 할 것입니다.
이러한 권한관리의 시작은 누가, 무엇을, 어느 리소스에 부여하느냐 입니다. 아시아 문화권에서는 철저하게 역할 별 권한을 주지 않고 개인벌 성향 및 사람들과의 관계 때문에 권한을 남용하는 사례가 벌어지는 경우가 있는데요.(관리하기 귀찮아서 수정권한을 팀원에게 모두 부여 하거나 친한 사람이라고 권한을 주거나 하는 경우 등) 이 때 보안위험에 노출될 수 있기 때문에 권환관리를 역할에 맞게 철저히 해야 합니다.
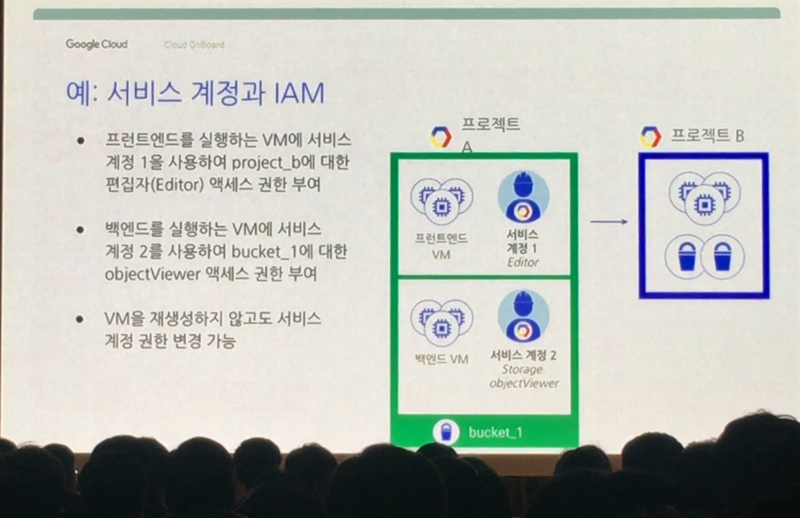
만약 한 사람이 두개의 프로젝트로 하나의 서비스를 운영하고 있는데 각 프로젝트 별로 담당하는 역할이 다를 경우 위와 같이 서비스 계정을 이용하여 처리할 수 있습니다. 가령, 프로젝트 A는 프론테엔드, 백엔드의 서비스 운영을 담당하고, 프로젝트 B는 프론트엔드의 데이터 처리를 담당하고 있으며 프로젝트 A의 프론트엔드만 프로젝트 B에 접근해야 한다고 해 보죠. 이 경우 담당자는 서비스계정이라는 것을 통해 프론트엔드 VM만 프로젝트 B에 접근할 수 있도록 권한을 부여할 수 있습니다. 즉, 프로젝트 안에서 서비스계정이라는 것을 이용하여 좀 더 세부적으로 권한을 관리할 수 있는 것입니다.

이제 본격적으로 Google Cloud Platform을 사용하는 방법에 대해 다뤄 보겠습니다. 위와 같이 4가지 방법으로 사용할 수 있는데요. Console은 많은 사람들에게 친숙한 Web UI형태 입니다. 클릭, 드래그 앤 드랍을 이용해 가상 머신 생성, 리소스 할당을 할 수 있죠. 또한 개발자들을 위해 CLI(Command Line Interface)도 제공합니다. 모바일 사용자를 위한 전용 앱도 있고요. 별도의 커스텀 애플리케이션 개발을 위해 API도 제공합니다.
저 같은 비전문가들의 경우 어떤 식으로 리소스를 구성해야 하는지 모를 수 있습니다. 프로젝트 별로 기본적인 구성을 담은 탬플릿을 제공하고(가령, 매출 분석과 같은 용도의 프로젝트를 하려면 VM별로 이정도의 리소스를 할당하고 이런 기술들을 사용해야 한다는 식으로 미리 구성해 둔 템플릿), 이것을 바탕으로 커스터마이징해서 사용할 수 있다면 더 좋을 것 같네요. 세션 중에 탬플릿에 대한 내용은 언급되지 않아서 확인을 못했는데, 이미 제공하고 있을 수도 있습니다.
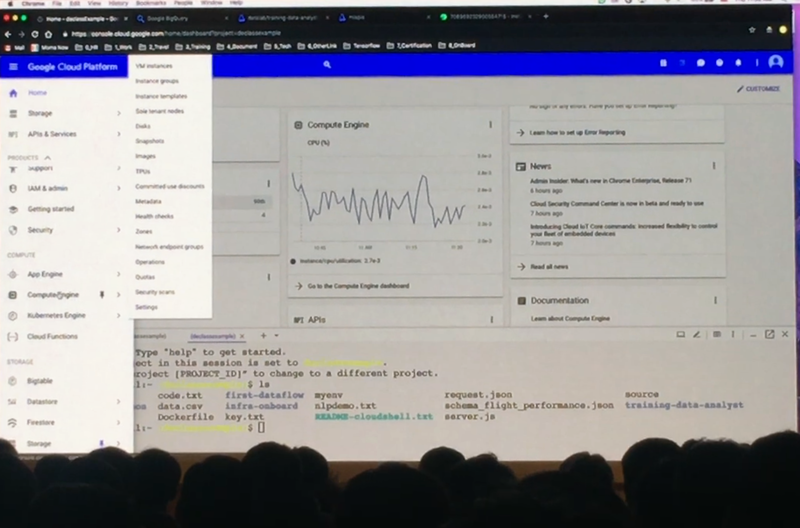
Google Cloud Platform의 Web UI와 CLI 데모입니다. 위 화면의 좌측에서 필요한 리소스 할당할 수 있고 아래와 같이 Command Line으로 할당할 수도 있습니다.
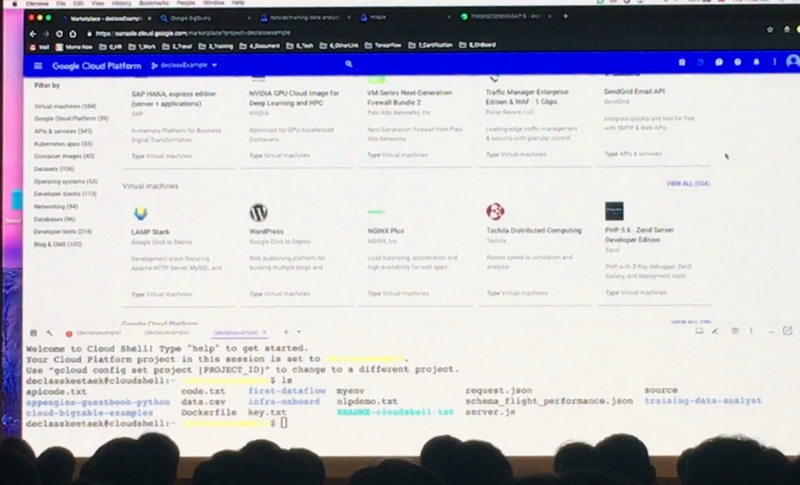
Google Cloud Platform은 Marketplace를 통해 다양한 벤더들의 서비스를 제공하고 있습니다. 가령 홈페이지 제작을 위한 워드프레스를 사용할 경우 이미 워드프레스를 위한 환경은 자동으로 설치가 되고 워드프레스에서 홈페이지를 만들기만 하면 됩니다. 이 모든 과정이 클릭 몇번으로 가능하며 사용자는 각 단계별 금액만 확인하고 사용하면 되는 것입니다. 비즈니스 니즈에 맞게 다양한 벤더들의 서비스를 선택하면 Google이 그 서비스 사용을 위한 인프라는 알아서 설정하여 제공하고, 사용자는 서비스를 사용만 하면 되는 것이죠. HW의 인프라에 대한 고민을 할 필요가 없다는 이야기 입니다. 전산담당자 분들의 환호성이 여기까지 들립니다? 아닌가요...??
모듈 3 클라우드 환경에서의 가상 머신
이번 모듈은 가상머신 입니다. 먼저 가상머신을 다루기 전에 네트워크 환경에 대한 이해가 필요한데요. 아래 장표를 보시죠.
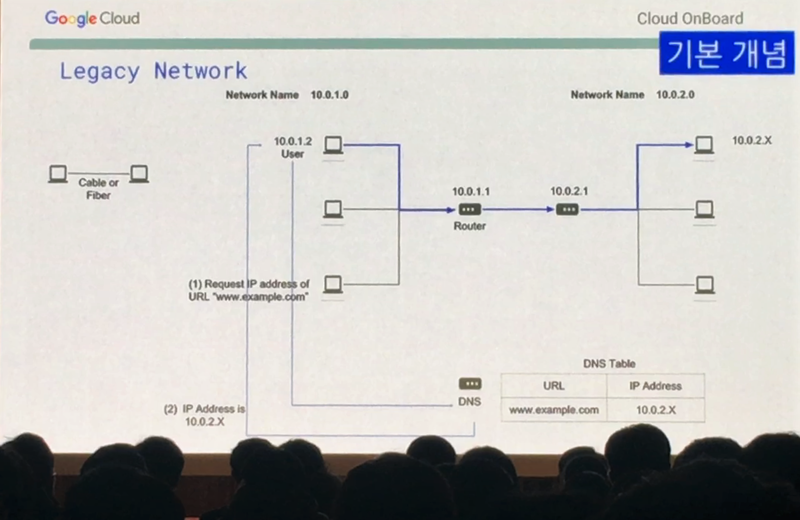
네트워크는 컴퓨터를 연결하는 것입니다. 두 대의 컴퓨터를 케이블로 연결하는 것이죠. 컴퓨터가 많아져서 여러대의 컴퓨터를 잘 연결하기 위한 방법을 토폴로지라고 하는데요. 하나를 가운데에 두고 연결하는 것을 스타형 토폴로지라고 하며(가장 많이 활용되는 토폴로지) 가운데에 라우터를 두고 이 라우터를 통해 컴퓨터를 연결하는 것입니다.
* 위 이미지에는 컴퓨터들을 중앙에서 연결해 주는 역할을 하는 것을 라우터라고 되어 있는데, 엄연히 말하면 허브 또는 스위치 장비가 이 역할을 합니다. 그리고 이 스위치 장비끼리 연결을 해 주는 것이 라우터이고요. 즉, 위 이미지의 라우터 앞쪽에 스위치가 있어야 하나 현장에서는 라우터로 통칭해서 설명했으니 참고하시기 바랍니다.
이렇게 연결한 네트워크 단위를 LAN(Locan Area Network, 근거리통신망) 이라고 부르고 이런 LAN들을 연결한 좀 더 규모가 큰 네트워크를 WAN(Wide Area Network, 원거리통신망)이라고 부릅니다.
이렇게 연결 된 컴퓨터끼리 통신하기 위해서는 주소가 필요한데요. 이 주소를 IP주소라고 부릅니다. 하지만 이 IP주소를 외우기 어렵기 때문에 DNS(Domain Name Server)를 이용하여 www.google.com에게 Google의 IP주소를 확인하고 접속하는 것입니다. 이것이 바로 기존의 전통적인 네트워크 환경입니다.

<이미지 출처 : zum 허브줌>
그런데 말입니다. 네트워크 규모가 커지고 복잡해 질 수록 라우터가 늘어나고, 라우터에 연결 된 컴퓨터가 많을 수록 업데이트 한번 할 때마다 엄청 번거롭게 됩니다. 그래서 나온 것이 바로 SDN(Sofrware-Defined Network)입니다.
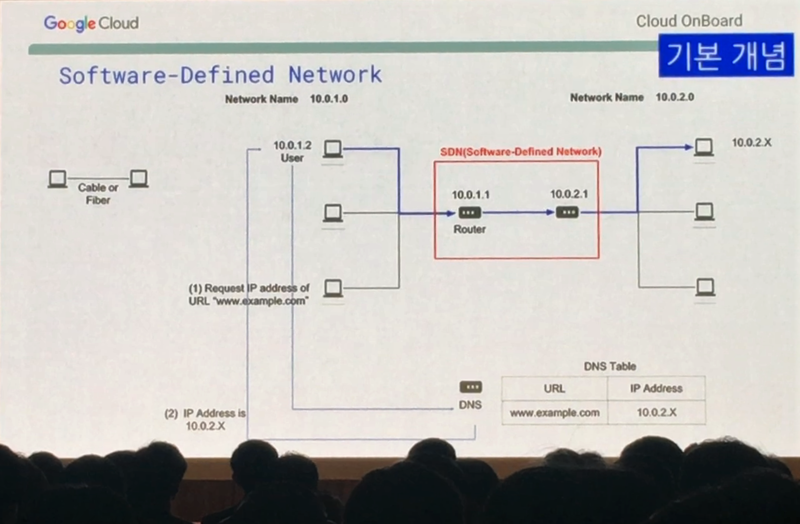
이 SDN을 통해 더 이상 네트워크 지역에 대한 범위를 벗어날 수 있습니다. 네트워크 규모가 아무리 크고 복잡하고 커버하는 네트워크 범위가 넓더라도 모두 한대 묶어 Software로 관리할 수 있게 된 것이죠. 더 이상 물리적인 위치는 중요하지 않으며 어떻게 구성하느냐가 중요해 진 것입니다.
Google은 전세계의 네트워크를 SDN으로 운영하고 있습니다. 전세계 어디에서 서비스 하든 그 지역의 네트워크를 중앙에서 손쉽게 관리할 수 있게 된 것이죠. 더 이상 네트워크 업데이트를 위해 각각의 라우터 별로 작업하지 않고 중앙에서 Software로 간편하게 작업할 수 있게 되었습니다. 그렇다면, 클라우드 환경의 네트워크는 어떨까요?
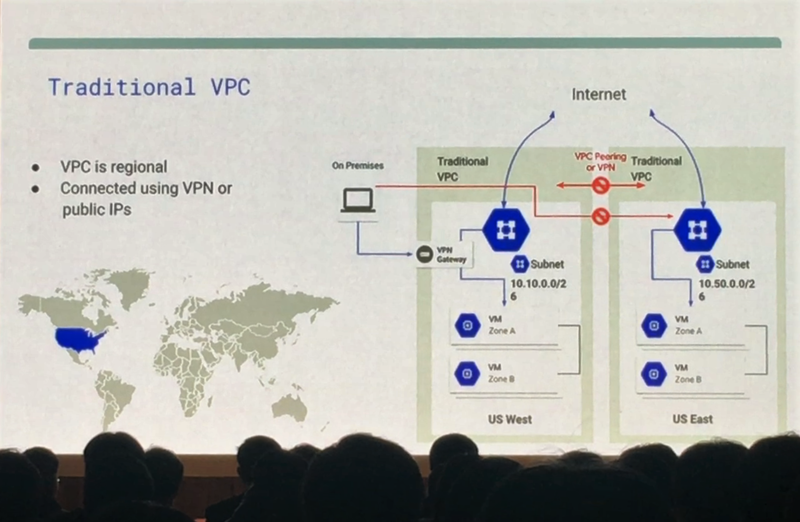
클라우드에서 사용하는 네트워크를 VPC(Virtual Private Cloud)라고 부릅니다. 기존의 클라우드는 리젼(지역) 별로 프로젝트를 생성했을 경우 기업의 온프레미스 환경에서 클라우드에 접속하려면 각 리젼별로 접속을 해야 합니다. 각 리젼이 독립된 네트워크 환경이라는 이야기 입니다.
만약 위 장표처럼 US West에 온프레미스 환경이 연결이 되어 있고, US West에서 US East의 데이터를 가져와야 한다면 US West에서 별도의 인터넷망 즉, VPN(Virtual Private Network)를 활용해서 인터넷을 통해 접속해야 합니다. 전용회선이 없고 각 지역의 ISP(Internet Service Provider)에서 제공하는 인터넷을 이용해야 하기 때문에 속도가 느릴 수 밖에 없습니다. 같은 클라우드 서비스를 이용 하더라도 반드시 인터넷 환경을 이용해 통신해야 하는 불편함이 있습니다.
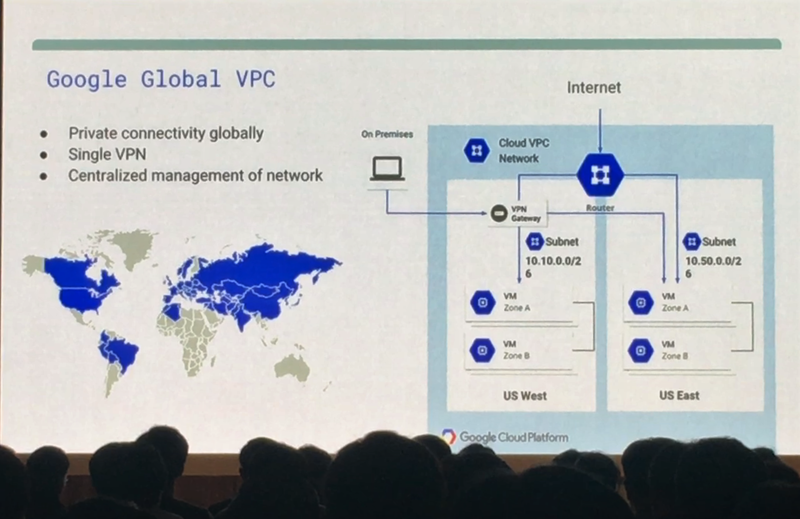
Google은 이 한계를 뛰어 넘었습니다. SDN으로 Google 네트워크를 모두 하나의 네트워크로 구성할 수 있는 것입니다. 프로젝트를 만들 때 네트워크를 최대 5개까지 만들 수 있으며 전세계 리젼 별로 네트워크를 5개까지 하나의 네트워크로 묶을 수 있다는 이야기 입니다. 이렇게 할 경우 군대에서 사용하던 인트라넷처럼 회사 내부에서만 이용하는 Internal IP로 통신할 수 있습니다. 두 리젼 사이에 통신할 때 기존의 클라우드 네트워크 환경보다 속도가 더 빠르고 인터넷망(External IP)을 거치지 않기 때문에 보안이 더 뛰어나겠죠. 즉, 지역별로 네트워크 구성을 위해 HW 인프라를 신경 쓸 필요가 없다는 것입니다.
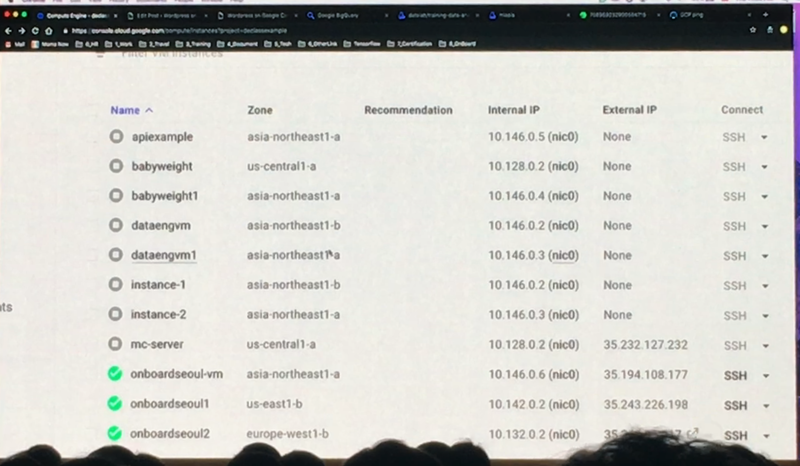
위 장표의 VM들은 각각 다른 리전의 네트워크를 사용하고 있지만 SDN으로 묶여있기 때문에 10.146.0.6과 같은 Internal IP로 통신할 수 있습니다. 좀 더 명확하게 이해하기 위해서 아래 예시를 살펴보죠.
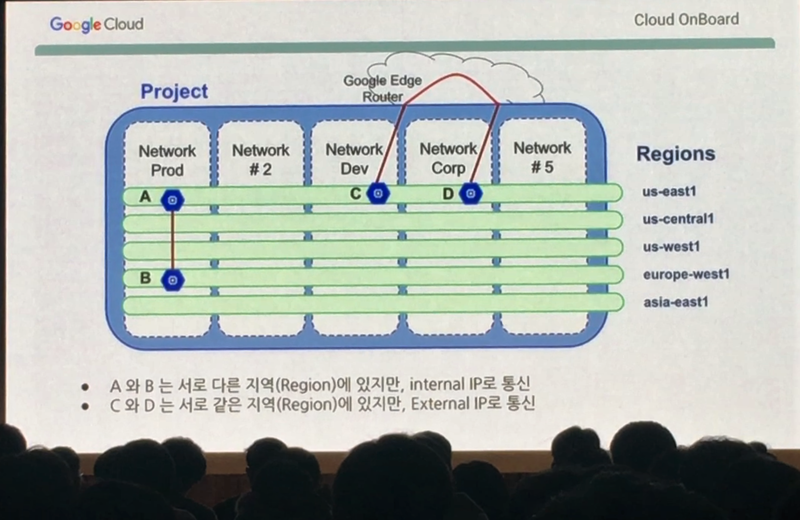
Google Cloud Platform에서는 하나의 프로젝트에 최대 5개까지 네트워크를 설정할 수 있다고 말씀 드렸습니다. 위와 같이 5개의 네트워크가 있고, 각 네트워크는 각기 다른 리젼의 네트워크 인프라를 이용하는데요. VM A와 VM B는 Network Prod라는 네트워크로 구성했기 때문에 Internal IP로 통신할 수 있습니다. 반면 VM C는 Networks Dev, VM D는 Network Corp라는 네트워크로 구성했기 때문에 같은 리젼에 있는 네트워크 인프라를 이용했더라도 서로 통신할 때 인터넷 즉, External IP로 통신해야 하는 것입니다. 지역은 전혀 문제가 되지 않고 어떻게 네트워크를 구성하느냐가 중요하다는 이야기가 되겠죠.
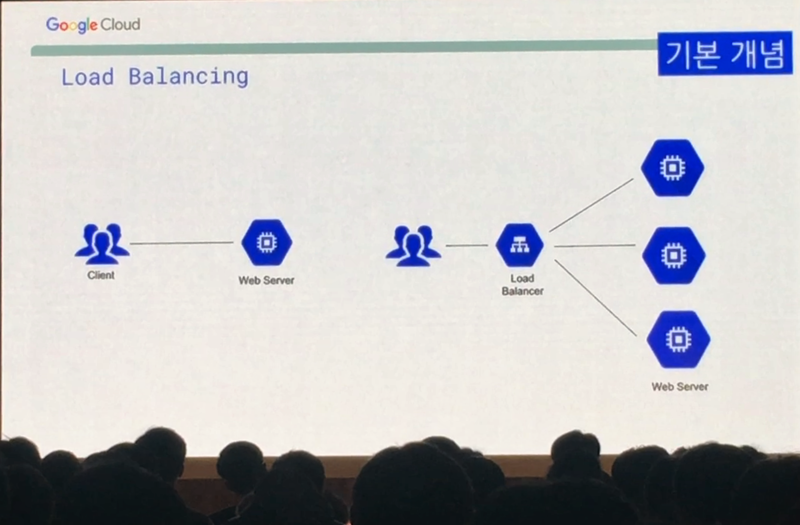
네트워크를 이야기할 때 빠질 수 없는 것이 바로 로드 밸런싱 입니다. 로드 밸런싱은 사용자가 특정 서비스에 접속할 때 갑자기 트래픽이 많이 몰릴 경우 이를 적절히 분산해 준다는 것인데요. 좌측 처럼 많은 사용자들이 하나의 웹서버에만 접속하게 된다면 갑자기 트래픽이 몰릴 경우 웹서버가 죽어서 서비스를 제대로 이용할 수 없습니다. 대학에서 수강신청 할 때 서버가 죽어서 수강신청 사이트가 안뜨거나, 쇼핑몰에서 타임세일 할 때 사용자들이 몰려서 쇼핑몰 상품 페이지가 느리게 뜬다거나 아예 안뜨는 경험 해 보셨을 텐데요. 이런 현상을 방지하기 위해 하나의 서비스를 여러대의 서버에 분산시켜 운영하는 것입니다.
위와 같이 여러대의 서버에서 하나의 서비스를 운영할 경우 앞단에 로드 밸런서를 두는데요. 사용자가 접속할 때 이 로드 밸런서가 뒷단의 웹 서버에 적절하게 트래픽을 알아서 분산시켜서 배분 해 주는 거죠. 고속도로 톨게이트의 하이패스 구간을 예로 들면, 총 8차선의 톨게이트에서 1,2 차선만 하이패스일 때 차량이 몰릴 경우 1,2 차선의 하이패스 줄이 길게 늘어져 톨게이트 입구부터 긴 병목 현상이 일어날 겁니다. 이 때 5,6 차선을 추가로 하이패스로 활용한다면 차량이 분산되어 병목 현상이 줄어들겠죠. 이것을 로드 밸런싱이라고 합니다.
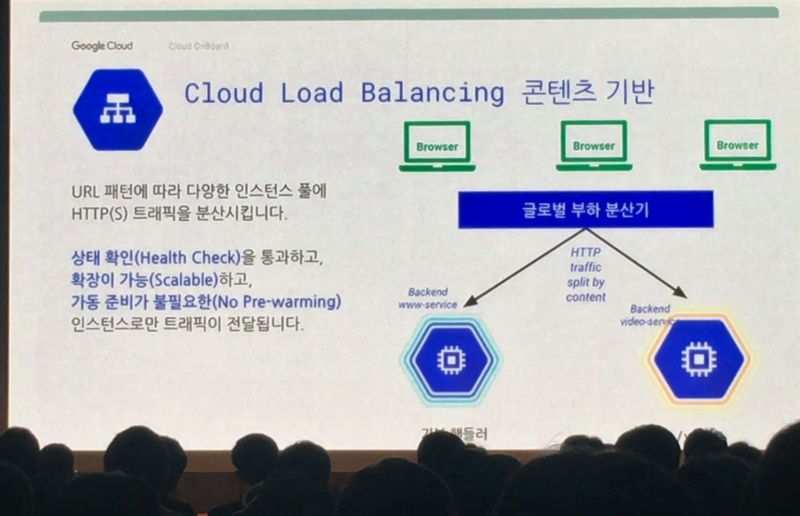
Google은 글로벌 서비스를 하는 서비스라 할 지라도 로드밸런싱을 통해 각 지역 별 서버가 죽었는지 살았는지 확인한 후 살아있는 곳으로 트래픽을 보냅니다. 또한 트래픽이 아주 많이 몰릴 경우 Auto Scailing을 통해 알아서 확장 해 주고 가동 준비 필요 없이 빠르게 작동합니다. 또한 콘텐츠에 따라서도 분산을 해 주는데요. 그냥 홈페이지를 둘러봐야 하는 트래픽이라면 웹서비스로, 동영상 스트리밍을 위한 트래픽이라면 비디오 서비스로 트래픽을 분산시켜 줍니다.

로드밸런싱보다 더 중요한 것이 DNS라고 할 수 있습니다. 이 DNS가 죽으면 서비스 접속 자체가 되지 않으니까요. 실제로 AWS가 최근에 DNS가 죽어서 뉴스에 나온적이 있었죠. Google은 100% SLA(Service Level Agreement)를 보장합니다. 왠만한 기업들도 99.5%, 99.7%라고 이야기 하지만 Google은 100%라네요. 그 만큼 자신있다는 것이고 안정적인 인프라를 빈틈없이 운영하고 있다는 반증이겠죠.

CDN(Content Delivery Network) 서비스 역시 제공합니다. 한국에서 만든 서비스를 미국에서 서비스해야 할 경우 미국 사용자가 한국 서버로 접속하면 속도가 느릴 수 밖에 없겠죠. 이 때 Google Cloud CDN은 미국 사용자가 미국 지역의 네트워크를 통해 접속하게끔 함으로써 보다 빠르게 서비스를 이용할 수 있게 해 줍니다. 우리가 한국에서 미국 서비스인 넷플릭스를 이용할 때 이 CDN서비스를 통해서 스트리밍 속도를 빠르게 하여 단시간에 고품질의 영상을 볼 수 있는 것이죠.(단, 이용하고 있는 ISP의 해외통신망 속도에 따라 다를 수 있습니다. 넷플릭스 볼 때 SKB는 느린 반면 KT는 빠른 이유가 여기 있습니다. 넷플릭스가 캐시서버를 한국에 두지 않았기 때문에 아직은 한국 외 지역의 캐시서버에서 데이터를 가져올 수 밖에 없거든요.

이후 Google에서 제공한 도시락으로 점심을 먹고 파트너 부스를 간단히 둘러 봤습니다. 클라우드 행사라면 빠지지 않는 베스핀글로벌, 메가존을 볼 수 있었고 삼성SDS와 락스페이스 부스도 볼 수 있었습니다. 모두 Google Cloud Platform의 Managed Service를 홍보하고 있었습니다. 'Google Cloud Platform 어렵죠? 우리가 알아서 잘 관리 해 드릴게요!' 라고 요약하면 너무 나간 것이려나요? 기업마다 제공하는 서비스가 세부적으로는 다를 테지만 결국은 이거라고 생각합니다.

이제 모듈3의 이어지는 내용인 Compute Engine을 정리 해 보겠습니다. 컴퓨터에서 가장 중요한 3가지는 스토리지, 메모리, CPU 입니다. 스토리지에 저장된 데이터를 메모리에서 받아서 CPU에서 처리하는 거죠. Google Cloud 인프라는 이러한 구글 만의 커스터마이징 된 CPU, Server, Storage, Network, Datacenter를 바탕으로 운영됩니다. 이 위에서 사용자는 내가 운영하려는 서비스의 CPU가 몇개가 필요한 지, 스토리지 용량은 얼마나 필요한 지 알려주면 Google Cloud Platform이 할당(프로비져닝) 해 주는 것이죠.

Google은 이렇게 만든 Compute Engine의 사용량을 보고 최적화 시켜 줍니다. 위 그래프에서 하늘색이 할당한 양, 파란색이 실제 사용하는 양 입니다. 보통 약간 더 여유있게 할당하는 것이 좋은데요. 할당시킨 것 대비 사용하는 양이 너무 적을 경우 해당 인스턴스의 크기를 조절하여 비용 절감 효과를 가져다 줄 수 있다고 합니다.
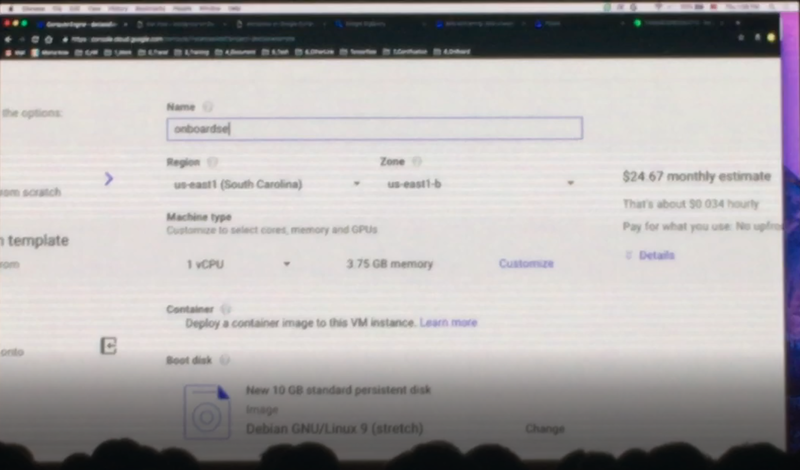
통상 vCPU 2개가 물리 CPU 1개 정도의 성능을 낸다고 합니다. 위와 같이 몇 번의 클릭과 드래그 앤 드랍으로 원하는 사양의 VM을 생성할 수 있는데요. 이 과정에서 Google은 CPU와 메모리를 한 세트로 묶고 스토리지와 분리 해 뒀습니다. 왜냐면 이 3개를 하나로 묶어 뒀을 때 빅데이터 분석을 위한 분산시스템 구성에 있어서 불편하기 때문인데요. 대용량의 데이터를 처리하기 위해서는 많은 양을 저장해 둬야 하는데 이 때 CPU와 메모리는 필요하지 않습니다.
반대로 빠른 분석을 위해서는 CPU와 메모리가 중요하니 많은 CPU와 메모리가 필요하겠죠. 이때문에 CPU와 메모리, 스토리지를 분리 해 둠으로써 각 용도에 맞게 간편하게 구성할 수 있도록 해 둔 것입니다.

또다른 특징 중 하나는 바로 Preemptible VM입니다. 아주 급하지는 않지만 대용량의 데이터 처리가 필요한 프로젝트의 경우 80% 저렴한 비용으로 사용할 수 있습니다. 유휴 자원을 다른 사용자가 요청했을 때 빌려주는 개념이기 때문인데요. MIT에서 수학연구과제 수행을 위해 22만개의 VM을 생성했는데 스토리지와 CPU, 메모리가 분리되어 있기 때문에 데이터는 스토리지에 저장되어 있고 다른 사용자에게 CPU, 메모리는 빌려줄 수 있습니다. 이렇게 온전히 그 자원을 내가 다 지금 당장 이용하는 것이 아니기 때문에 이용요금을 80%까지 할인받을 수 있는 것입니다.
모듈 4. 클라우드 스토리지
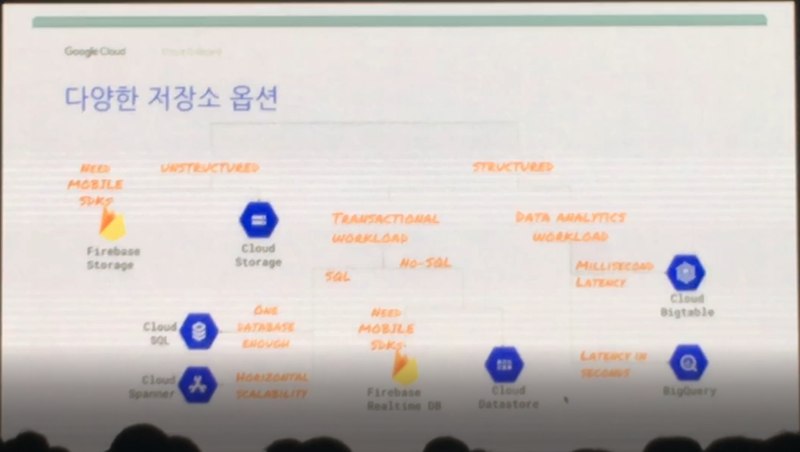
Google Cloud Platform은 다양한 스토리지 옵션을 제공합니다. 데이터 유형에 따라서 다른 스토리지 옵션을 활용하면 되는 것인데요. 먼저 데이터 유형 및 그에 맞는 Google Cloud Platform에서 제공하는 제품에 대해 정리 해 보겠습니다.
- 정형 데이터 = 테이블 형태
i. OLAP(Online Analytical Processing) : 분석을 위한 데이터, BigQuery는 빠른 분석, BigTable은 대용량 분석에 활용
ii. OLTP(Online transaction processing) : 업데이트가 빈번한 실시간 데이터
* Cloud Spanner는 아주 큰 테라 단위의 SQL 데이터(테이블 형태)를 처리할 때 활용
* Cloud Datastore는 NoSQL(키 값 형태)를 처리할 때 활용
- 비정형 데이터 = 텍스트, 이미지, 오디오, 비디오
i. 이미지가 왜 비정형 데이터인가? 컴퓨터는 가로세로로 잘라 작은 네모로 쪼개어(픽셀) RGB값으로 변환 후 0과 1로 저장하기 때문

비정형 데이터 저장을 위한 Cloud Storage 이용 가격은 각 저장하는 가격(저장소 이용 용량에 비례)과 가져오는 가격(저장 된 데이터를 가져올 때 전송되는 데이터 용량에 비례)에 좌우됩니다. 이때문에 데이터 특성에 따라서 옵션을 선택해야 하는데요. 위 표와 같이 Google은 4가지 옵션을 제공하고 있습니다.
아주 가끔 들여다보는 DR용 데이터는 저장용량 당 가격이 저렴한 Coldline에, 자주 접근해야 하는 데이터는 가져오는 가격이 저렴한 Multi Regional 옵션을 활용하면 좀 더 비용 효율적으로 활용할 수 있습니다. 데이터의 목적에 맞게, 사용 빈도에 맞게 적절한 옵션을 선택하는 것이 중요한 것이죠.

Cloud SQL은 Google이 제공하는 RDBMS라고 보시면 됩니다. 기존 온프레미스 환경의 데이터를 그대로 가져올 수 있는데요. 데이터의 양이 GB단위일 경우 활용하시면 좋습니다. 만약 TB 혹은 PB 단위의 방대한 데이터라면 어떻게 해야 할까요? Cloud Spanner를 사용하면 됩니다.

Cloud Spanner는 수평으로 확장 가능한 RDBMS입니다. 똑같은 RDBMS를 옆으로 쭉쭉 늘려나간다고 보시면 되는데요. HA가 보장되고 8,000 QPS(Query per second) 이상의 처리가 필요할 때 기존의 SQL 처리를 위한 RDBMS대비 확장이 쉽기 때문에 더 많은 양의 QPS를 감당할 수 있습니다.(기존의 일반적인 MySQL같은 RDBMS는 8,000 QPS가 넘어가면 레이턴시(지연)이 확 늘어난다고 합니다.) 그냥 옆으로 쭉쭉 노드만 늘려나가면 되는 겁니다. 2만 정도의 QPS를 처리할 수 있다네요.

이번에는 테이블 형태가 아닌 키값 형태의 데이터인 NoSQL 제품입니다. 먼저 Cloud Bigtable은 어마어마하게 큰 표라고 생각하시면 되는데요. 수백만행, 줄로 이루어져 있다는군요. 머신러닝을 위한 데이터나 IoT기기에서 수집된 데이터 저장에 적합하며 Google Analytics, Gmail에서 사용하고 있다고 합니다. 성능 역시 Spanner처럼 노드만 추가하면 QPS가 선형적으로 늘어납니다. 처리할 수 있는 양이 무려 4백만 QPS가 넘는다는군요.

Bigtable을 사용할 만큼의 데이터 양이 아니고 훨씬 적은 양이라면 Datastore를 이용하면 됩니다. Autoscailing이 지원되기 때문에 데이터 양이 늘어나면 알아서 노드를 늘려주는 똑똑한 NoSQL DBMS입니다.
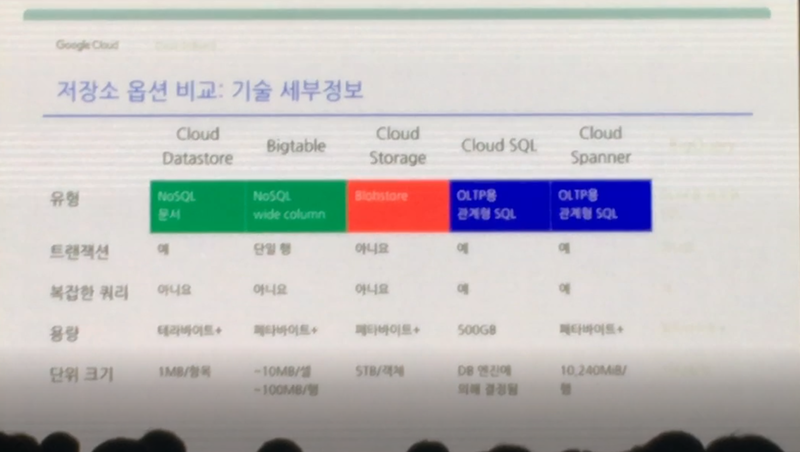
요약하면 위 장표와 같습니다. 왼쪽의 Datastore는 NoSQL문서같은 데이터를 Google App Engine 애플리케이션에서 저장할 때 사용하고 Bigtable은 엄청나게 많은 양의 NoSQL 데이터를 사용하는 광고업계, 금융권에서 주로 사용합니다. Cloud Storage는 이미지, 대용량 미디어 파일 및 백업용 데이터 저장을 위해 사용하고, Cloud SQL은 기존 RDBMS와 마찬가지로 사용자 인증 정보, 고객 주문데이터 등 웹서비스의 저장 용도로 사용하면 됩니다. Cloud Spanner는 2TB이상의 대규모 OLTP 데이터를 저장할 때 사용합니다.
모듈 5. 클라우드 컨테이너 서비스
아마 클라우드에서 머신러닝과 더불어 최근에 가장 핫한 주제가 아닐까 싶습니다.

IaaS(Infra as a Service, Compute Engine)는 자원을 할당한 만큼 지불합니다. PaaS(Platform as a Service, App Engine)는 사용한 만큼 지불합니다. 컨테이너인 Kubernetes Engine은 이 IaaS와 PaaS의 중간에 위치하고 있습니다. 그럼 이 컨테이너의 개념을 정리해 보 겠습니다.
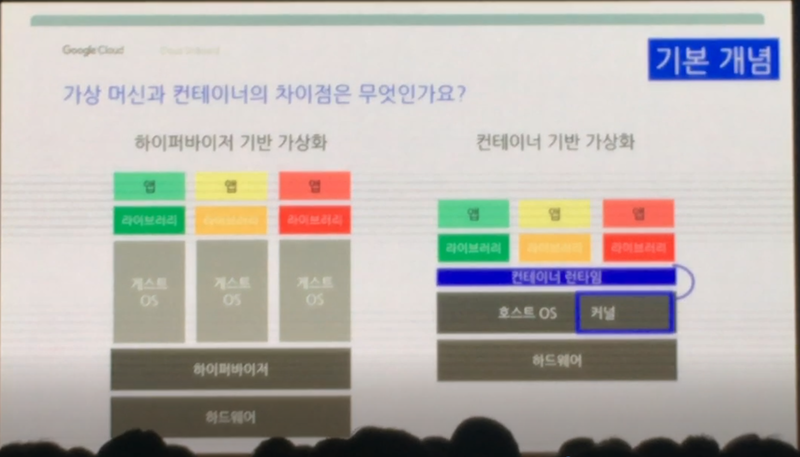
먼저 특정 애플리케이션(SW)를 구동하기 위해서는 HW에서 바로 구동이 되지 않기 때문에 OS(Operation System)가 필요합니다. HW를 조작하기 위해 나온것이 OS입니다. OS위에서 애플리케이션을 여러개 돌리다보면 HW성능 한계로 인해 애플리케이션 동작 속도가 느려지게 되는데요. 서로 충돌나는 경우도 생기죠. 그래서 여러개의 애플리케이션을 독립적으로 구동하고 싶은 욕구가 생겼고 이를 해결하기 위해 나온 기술이 바로 가상화 기술입니다.
하이퍼바이져는 VM(가상머신) 위에 개별 OS 여러개를 설치하고 이 개별 OS위에서 애플리케이션을 구동하는 것이 VM 기술입니다. 똑같은 HW라고 하이퍼바이져를 통해 VM을 여러개 만들어서 Windows용 애플리케이션과 Linux용 애플리케이션, macOS용 애플리케이션을 실행시킬 수 있다는 거죠.
그런데, 이렇게 애플리케이션을 각각 독립된 OS 위에서 돌려야 하기 때문에 애플리케이션 수 마다 OS가 필요합니다. 즉 100개 애플리케이션을 실행시키려면 100개의 OS가 필요하다는 것이고 HW에 주는 부담 역시 커지기 마련 입니다. 그래서 이것을 좀 더 애플리케이션에 맞게 효율화 시킬 수 없을까 하는 고민에서 탄생한 것이 컨테이너 입니다.
VM은 하이퍼바이져를 통해 여러개의 OS를 설치하고 그 위에서 애플리케이션을 운영하지만, 컨테이너는 하나의 OS위에 애플리케이션 구동을 위한 공간을 마련하고 그 위에서 애플리케이션을 운영합니다. 기존 VM대비 다수의 애플리케이션 운영을 위해 다수의 OS를 운영할 필요가 없게 된 것이죠. 간단히 이야기 하면 기존 VM대비 좀 더 가벼운 가상화 기술이라고 보시면 되겠습니다. Google은 매주 40억개의 컨테이너를 실행하고 폐기한다고 하네요.

컨테이너의 등장으로 애플리케이션 수 만큼 너무 많은 컨테이너가 만들어 지게 되었습니다. 자연스럽게 이 많은 컨테이너를 어떻게 간편하게 관리하느냐가 중요해졌죠. 그래서 나온 것이 Kubernetes 입니다. Kubernetes는 Google이 개발한 오픈소스로 컨테이너 배포, 확장, 운영을 자동화 시킵니다. 다양한 클라우드 환경을 지원하며(Public, Private, Hybrid) 오픈소스이기 때문에 AWS, Azure에서도 사용이 가능합니다.

Kubernetes Engine은 Google Cloud Platform에서 Kubernetes를 운영하는 것을 뜻합니다. Docker를 이 Kubernetes Engine으로 Google Cloud에서 배포시키고 관리할 수 있다는 거죠. 온프레미스 환경에서는 Google Network에 연결하여 Kubernetes Engine을 활용할 수 있고 실제 금융권에서 이렇게 많이 사용하고 있다고 합니다.
Kubernetes를 활용하면 다수의 컨테이너를 단일 시스템인것 처럼 관리할 수 있습니다. 컨테이너는 VM대비 그 수가 많을 수 밖에 없기 때문에 관리 편의성이 매우 중요한데요. 그래서 마이크로서비스(애플리케이션을 구동에 위한 최소한의 요소들로만 구현하여 빠른 배포, 실행, 폐기가 가능)가 유행인 요즘 Kubernetes가 각광받고 있는 것입니다.
모듈 6. 클라우드 애플리케이션
앞의 모듈 5까지 소개 해 드린 많은 내용은 애플리케이션 운영을 위한 환경에 대한 제품과 기술들입니다. 그렇다면 이러한 환경에서 애플리케이션을 개발하기 위한 플랫폼인 App Engine에 대해 정리 해 보겠습니다.

App Engine은 Google Cloud Platform에서 가장 먼저 나온 서비스 입니다. PaaS(Platform as a Service)이며 하루 App Engine 요청 건수가 무려 3,200억건이라고 합니다.(위키피디아가 2,700억건이라네요.) 개발자들은 애플리케이션 운영과 개발을 위한 환경은 Google에 맡겨두고 코드만 잘 짜면 되는 것입니다.
이 App Engine은 Autoscailing을 지원하는데요. 애플리케이션을 사용자들이 시간에 따라 얼마나 많이 사용할 지 예측이 어렵기 때문에 리소스 할당에 고민이 많을 수 밖에 없습니다. 이 때문에 App Engine은 사용자들의 수요가 많고 적음에 따라 자동으로 리소스 할당을 해 줍니다. Cloud가 제공해야 할 가장 중요한 기능이 바로 Autoscailing이 아닐까 합니다.

App Engine은 두 가지 개발 환경을 제공합니다. 먼저 Standard Envirnment는 컨테이너 기반으로 돌아가며 Java, Python, PHP를 지원하고 모든 언어를 지원하지는 않습니다. 그리고 샌드박스(독립된 공간)에서 구동되기 때문에 다른 SW를 설치하기 어려운 단점이 있지만 이 때문에 속도 자체는 빠릅니다.
위와 같이 App Engine Standard 환경에서 웹 애플리케이션을 개발할 때 개발자는 로컬 환경에서 애플리케이션을 개발하고 테스트 한 뒤 이상 없으면 App Engine에 배포합니다. 그러면 App Engine이 애플리케이션 수요에 따라 자동으로 리소스를 할당하고 확장해서 잘 운영하고 관리해 줍니다. API를 통해 다른 서비스와도 연결할 수 있습니다.

두 번째는 Flexible Environment 입니다. Standard의 단점을 해결했지만 속도가 느리고 시간 당 리소스 할당량 만큼 지불하는 환경입니다. Standard 대비 다양한 언어를 지원합니다. 두 환경을 비교해 보면 아래와 같습니다. 아래 비교표를 통해 개발 여건을 따져보고 App Engine을 활용하면 되겠습니다.

모듈 6의 마지막 내용은 API입니다. API는 Application Programing Interface의 약자로 애플리케이션들의 통신을(의사소통을) 도와주는 기술입니다. 클라우드는 이 API의 집합소라고 할 수 있겠습니다. 수 많은 API가 서로 상호 연결되어 운영되니까요.

수 많은 API가 존재하는 클라우드 세상에서는 이 API를 관리하고 유지보수 하는 것이 큰 이슈입니다. Cloud Endpoints는 API 콘솔로 API를 간편하게 생성하고 관리할 수 있게 해 줍니다. Google Clouod의 App Engine, Compute Engine, Kubernetes Engine을 지원합니다.
모듈 7. 클라우드에서 개발, 배포, 모니터링

Google Cloud Platform을 활용하여 개발하실 때 많은 개발자들과의 협업을 위해 개발 전용 저장공간을 제공합니다. 이 Source Repositories를 통해 공동으로 앱을 개발하고 디버깅 할 수 있습니다. Stackdriver Devugger는 후반에 다시 정리 하겠습니다.

Cloud Funcions는 완벽한 서버리스로 동작하는, 애플리케이션에 적용 될 함수를 만들어 적용하는 제품입니다. 간단한 동작을 위한 함수가 필요할 때 활용하시면 됩니다.(하지만 전 개발자가 아니라서.... 뭐하는 제품인지 솔직히 잘 감은 안옵니다.)

클라우드 환경에서 개발이 끝났으면 이제 배포를 해야겠죠. Cloud Deployment Manager를 활용하면 됩니다. 모듈 1에서 Market Place를 설명 드리면서 워드프레스를 보여드렸는데요. 그 워드프레스도 이 Deployment Manager를 통해 사용자가 할당한 VM에 배포가 되는 것입니다.
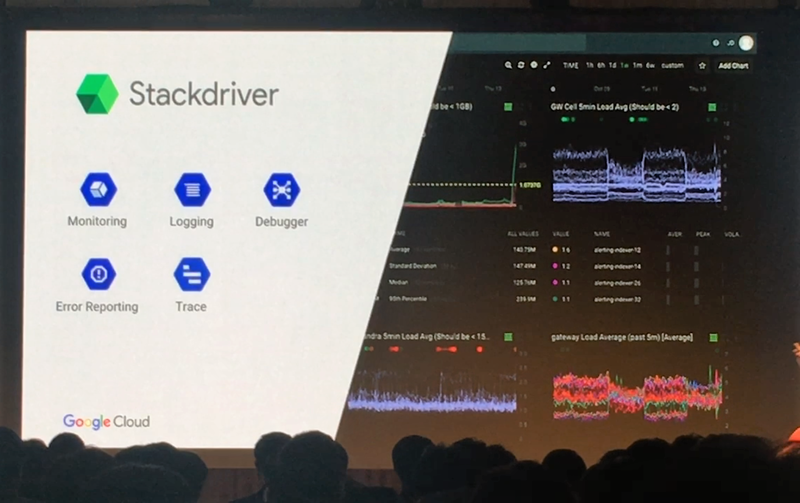
Stackdriver는 Google Cloud Platform의 통합 모니터링을 제공합니다. 심지어 이 Stackdriver를 통해 AWS같은 다른 클라우드도 모니터링할 수 있습니다. 단순히 현황 모니터링 뿐만 아니라 내가 사용한 리소스 양에 대한 과금이 얼마나 될 것인지에 대한 빌링 모니터링도 가능합니다.
모듈 7은 이렇게 간단히 마치고 오늘 모듈 중 가장 양이 많은 모듈 8로 넘어가겠습니다. 마지막 모듈이지만 앞에 설명 드렸던 모듈 1~7까지 합친 것 만큼 양이 많습니다. 그 만큼 중요하고 요즘 가장 핫한 주제이니만큼 잘 정리 해 보겠으니 끝까지 집중력 잃지 마시고 봐 주세요!
모듈 8. 클라우드 빅데이터 및 머신러닝
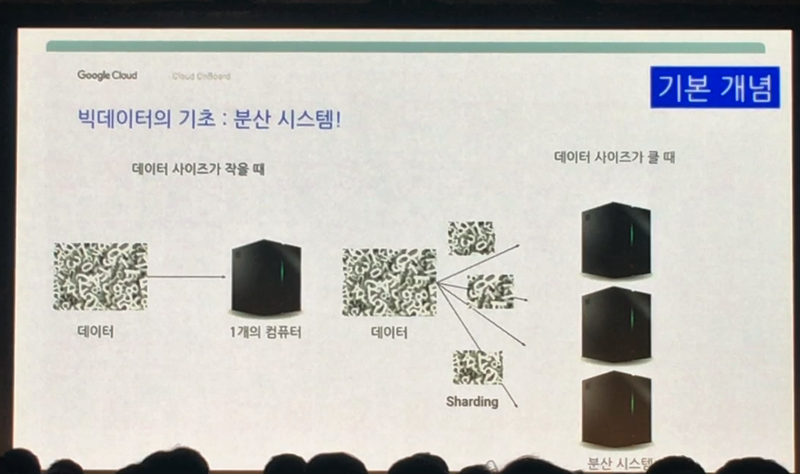
먼저 빅데이터의 분산시스템 개념에 대해 이야기 해 보겠습니다. 빅데이터는 하나의 컴퓨터, 즉 서버에 저장하기 어려울 정도로 방대한 양의 데이터를 말합니다. 이 큰 데이터를 잘개 쪼개서(샤딩) 여러 컴퓨터에 저장(맵) 합니다. 그리고 여러대의 컴퓨터가 동시에 처리(분산) 합니다. 이후 이 계산 결과를 조정(마스터) 및 계산(워커)하고 합치는 것(리듀스)를 분산시스템이라고 부릅니다.
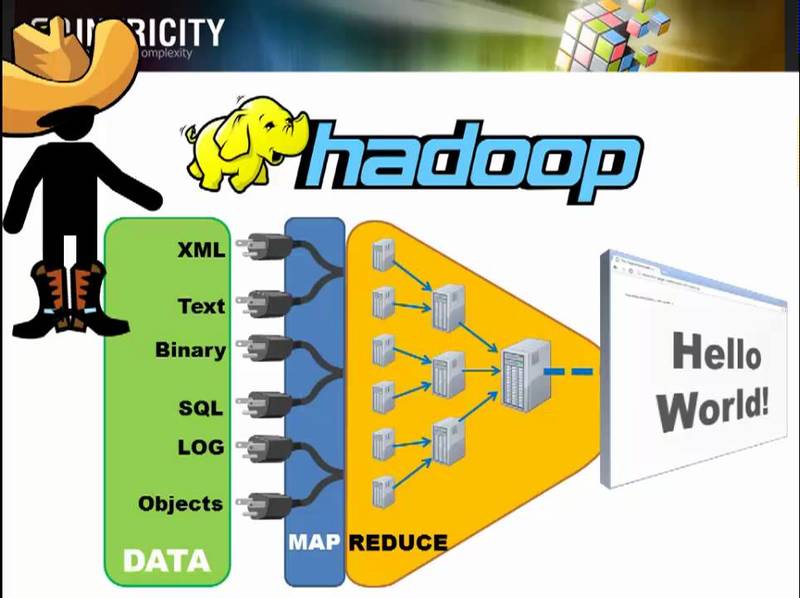
<이미지 출처 : Youtube, What is Hadoop?>
이렇게 Google의 방대한 데이터에 맵리듀스 알고리즘을 적용하고 분산시스템으로 처리 해 보니 너무 좋아서 오픈소스 커뮤니티에 관련 기술을 공개합니다. 이 기술을 많은 전문가들이 달라붙어 발전시킨 것이 바로 Hadoop 입니다. 아마 빅데이터 처리에서 가장 많이 언급되는 것이 Hadoop(하둡)이고 이 Hadoop을 이야기 할 때 맵리듀스라니 샤딩이니 라는 단어를 많이 접하셨을텐데요. 저도 이제서야 이해가 되었습니다.
정리하면, 분산시스템이란 큰 사이즈의 데이터를 여러개의 컴퓨터가 동시에 계산해서 작업을 하는 시스템을 말합니다. 이 Hadoop을 기반으로 다양한 Hadoop Eco System이 발전되어 분산시스템이 가능한 다양한 오픈소스들이 나왔습니다. 그렇다면 기존 온프레미스 환경에서 이러한 분산시스템을 구축하려면 어떻게 해야 할까요?
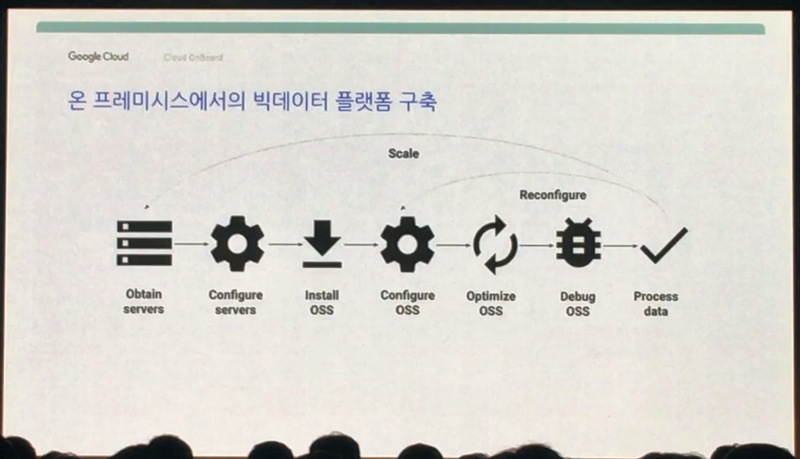
일단 많은 HW가 필요하겠죠. 인프라를 준비해서 세팅을 하고 오픈소스를 설치하고 다시 조정하고 데이터를 올리고 처리 해 봅니다. 이 때 문제가 발생하면 다시 디버그하고 조정하는 과정을 거칩니다. 그렇게 데이터를 처리하는데 이런, 데이터가 너무 큽니다. 그러면 어떻게 해야 할까요? 네, 다시 HW인프라를 추가로 준비해서 위 과정을 다시 거쳐야 합니다........
대기업이라 할 지라도 위와 같은 빅데이터 분석을 위한 분산시스템을 구축하는 데에 2~3개월은 너끈히 걸린다고 합니다. 그러면 이제 어찌해야 할까요. 대기업도 2~3개월 걸리는데 우리가 온프레미스 환경에서 몇 개월씩 투자해서 HW구축하고 세팅하고 할 수 있을까요? 매우 어렵습니다.

그래서 Google Cloud Platform의 Hadoop인 Dataproc을 사용해야 합니다. 클로스터(여러 컴퓨터의 집합) 만들고 조정하고 사용할 수 있는 환경이 만들어 지는 데에 까지 딱 90초면 됩니다. 3개월 걸리던 작업이 이제 90초면 끝납니다. 심지어 HW투자비용도 안듭니다. Google Cloud Platform에서 VM만 만들면 되거든요.(실제 데모시연에서도 드래그 앤 드랍으로 몇 분만에 분산시스템 구축이 끝났습니다.) 이래도 클라우드 활용 안하시겠어요? 저는 1초도 고민 안할 것 같습니다.

PB 단위의 아주 큰 데이터를 처리하기 위해서는 BigQuery가 필요합니다. 기존 DB엔지니어 분들도 손쉽게 이용하실 수 있도록 SQL 구문을 사용하며 최대 2,000개의 슬롯들이 분산처리를 실행하기 때문에 처리 속도가 매우 빠릅니다. 데모시연에서는 400GB를 처리하는 데 딱 14초 걸리더군요.

기존의 RDB에서는 각 DB의 각 모든 컬럼을 조회하여 데이터를 추출했다면 BigQuery는 컬럼별로 저장하여 필요한 컬럼만 조회하기 때문에 빠르게 처리가 가능하며 테라비트급 네트워크로 동작합니다. 사용자는 처리에 사용된 저장용량에 대해 지불하면 되는데요. 시장에서 경쟁가능한 제품이 없을 정도로 강력한 제품이라고 하는데 진짜 그런 것 같습니다.
이렇게 분산시스템을 구축 해 두면 이제 처리해야 하는 데이터를 수집해야 합니다. 만약 실시간으로 데이터가 수집된다면 이 실시간 데이터를 잘 받아서 수집해야 하는데요.(이런 역할을 하는 것이 바로 미들웨어 입니다.) 이 데이터 수집 방법에는 두 가지가 있습니다.
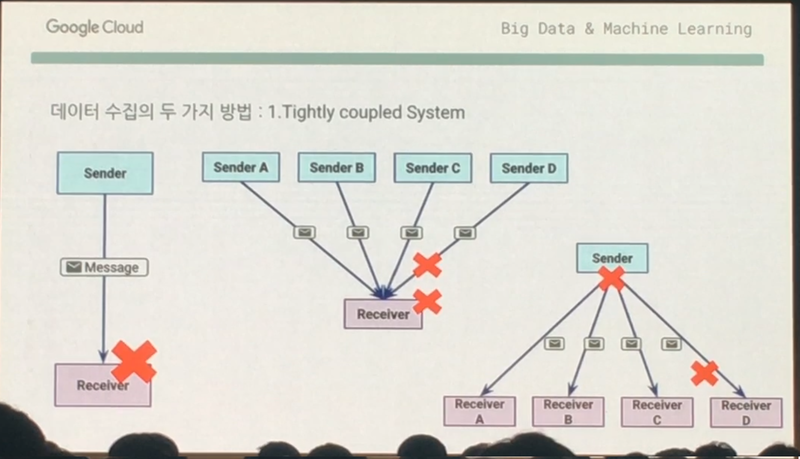
첫 번째는 Tightly coupled System 입니다. 메세지를 보내는 센더와 받아주는 리시버를 연결하는 것인데요. 우편등기시스템을 생각하지면 됩니다. 이 구조에서는 리시버(서버)가 다운됐을 경우 센더의 메세지가 유실되는데요. 여러명의 센더가 동시에 메세지를 보내면 리시버가 제대로 못받을 수 있고, 이때 메세지를 잃어버릴 수 있는 위험이 있는 거죠.
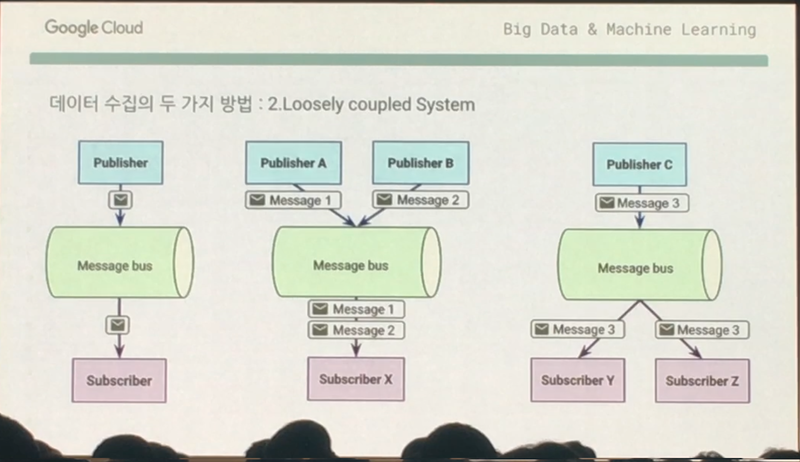
두 번째는 Loosely coupled System 입니다. 센더가 중간에 위치한 메세지버스로 메세지를 보내고, 메세지버스는 리시버가 다운됐다면 그냥 메세지를 보관하고 살아있다면 보냅니다. 이 메세지버스가 안정적이고 사이즈가 크다면 여러 센더가 메세지를 보내더라도 메세지 유실 위험이 줄어들게 되겠죠. 즉, 메세지버스 의존도가 높은 구조라고 보시면 되겠습니다.

Pub/Sub은 Google 검색, Gmail에서 사용해온 메세지버스 입니다. 10억명의 사용자를 대상으로 검증되온 강력한 메세지버스라고 보시면 되겠습니다. Google 검색이 제대로 돌아가지 않거나 Gmail에서 메일을 못받은 경험은 아마 없을 것입니다. 그 정도로 안정적인 서비스인데요. 실시간 스트리밍 데이터를 잘 받아줄 수 있고 시장에서 경쟁자가 없을 만큼 뛰어난 제품이라고 합니다.

Dataflow는 실시간 데이터(Stream)와 정형화 된 파일형태의 데이터(Batch)를 동시에 처리해야 할 때 활용하면 좋습니다. 카드회사의 경우 시간대 별 결제 데이터 분석을 위해, 게임회사에서는 핵을 이용하는 불법 이용자를 잡아내기 위해 실시간 + 과거 데이터를 함께 분석해야 하기 때문에 많이 이용한다고 합니다. 또한 서버리스로 동작하고 Autoscailing을 지원하기 때문에 시간대 별로 데이터 양에 따라 안정적으로 운영할 수 있습니다. Google이 개발한 오픈소스인 아파치 빔 기반이고 Python, Java 기반이라 자유도가 높은 장점이 있습니다.

마지막으로 데이터 분석 결과를 관리하고 시각화할 때 Datalab을 활용합니다. 오픈소스인 쥬피터 기반이며 Python Library를 활용하여 차트를 통해 시각화 할 수 있습니다.
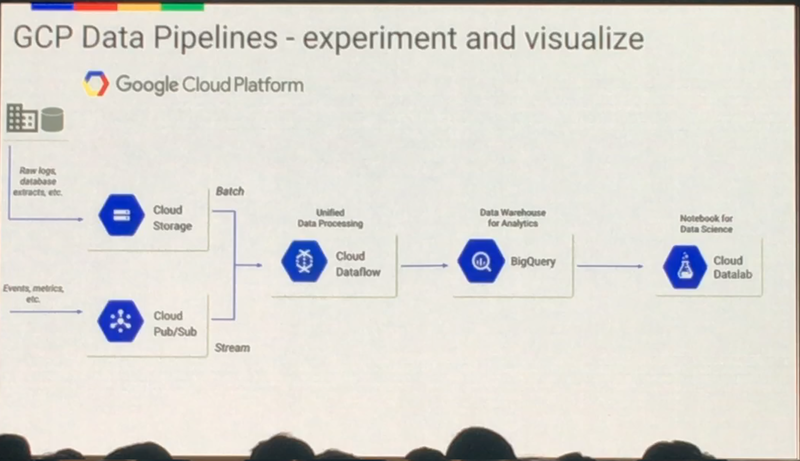
전체 데이터 처리의 흐름을 보면 위와 같습니다. Cloud Storage와 Pub/Sub에서 Batch 데이터, Stream 데이터를 수집하여 Dataflow로 보냅니다. Dataflow는 두 유형의 데이터를 동시에 처리하고 BigQuery를 이용하여 대용량의 데이터를 분석하고 Datalab으로 데이터과학자가 연구하여 유의미한 결과물을 뽑아내는 것입니다. 여기까지 빅데이터에 대한 내용이었고, 이제 머신러닝으로 넘어가겠습니다.

머신러닝이란 AI의 한 분야로, 기계 즉 컴퓨터가 학습할 수 있도록 개발한 알고리즘 및 기술을 말합니다. Google에서 제공하는 머신러닝은 크게 3가지 입니다. 아래와 같이 간단히 정리할 수 있겠습니다.
- Machine Learning API
i. 이미 Google이 가진 데이터로 학습 시켜 놓았으며 API형태로 제공
ii. 사용자는 가져다가 결과 예측 등 목적에 맞게 활용하면 됨
- Cloud AutoML
i 코딩을 잘 못하는 사람들을이 쉽게 머신러닝을 다룰 수 있게 하는 제품으로 드래그 앤 드랍 UI 사용
ii. 사용자가 직접 데이터를 업로드하여 학습을 시킴
iii. 비정형데이터 기반의 데이터 분석 가능 : 오디오, 비디오, 이미지, 텍스트 번역 등
- Cloud ML Engine
i. TensorFlow 코드 활용, Compute Node만 Google Cloud Platform에서 설정하면 됨
ii. 대학 연구실에서 머신러닝 모델을 만들어도 운영할 수 있는 여건이 되지 못해 이 ML Engine을 활용함
iii. 사용자가 직접 코드를 짜야하기 때문에 자유도는 높으나 진입장벽이 높음

Google Machine Learning Platform은 비정형데이터를 미리 다 학습시켜 두었고 이를 API로 제공하고 있습니다. 이미지 분석은 Vision API, 비디오는 Video Intelligence API, 번역은 Translation API, 텍스트 분석은 Natural Language API를 활용할 수 있습니다. 비정형데이터 분석은 여전히 어려운 분야입니다. 사람과 달리 컴퓨터는 사진을 보고 여기가 서울시청인지 남산타워인지 바로 인지하기 어렵습니다. Google은 이런 것들이 가능해 지기 위해 오랫동안 Google 서비스에서 수집한 데이터를 통해 학습시켜 왔습니다.
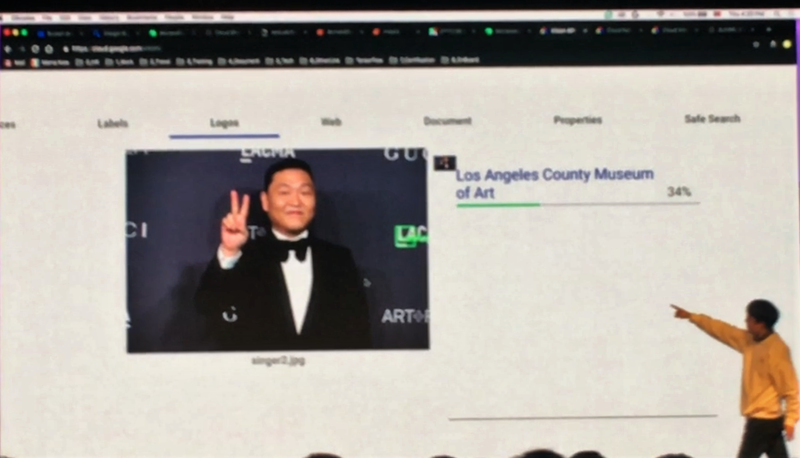
이미지 분석을 위한 Vision API는 위와 같이 싸이의 이미지에서 LAC라는 글자를 보고 이 사진을 찍은 곳이 Los Angeles County Museum of Art라는 것을 밝혀 냈습니다. 단순히 장소 뿐만 아니라 싸이와 관련된 수십가지의 항목을 분석 해 냅니다.
그리고 이것을 API로 제공하기 위해 JSON형태로도 보여줍니다. Vision API는 이미지에서 유용한 정보 확보, 부적절한 콘텐츠 감지(음란물 등), 이미지 인물의 정서, 감정 분석, 텍스트 추출을 할 수 있습니다.

Speech API를 활용하면 80개 이상의 언어를 인식하여 실시간으로 텍스트로 변환하고, 이 변환된 텍스트를 해당 언어로 말해줍니다. 그리고 이 목소리가 알파고로 유명한 딥마인드에서 개발한 Wavenet을 통해 실제 사람처럼 자연스러운 목소리를 들려준다고 합니다.
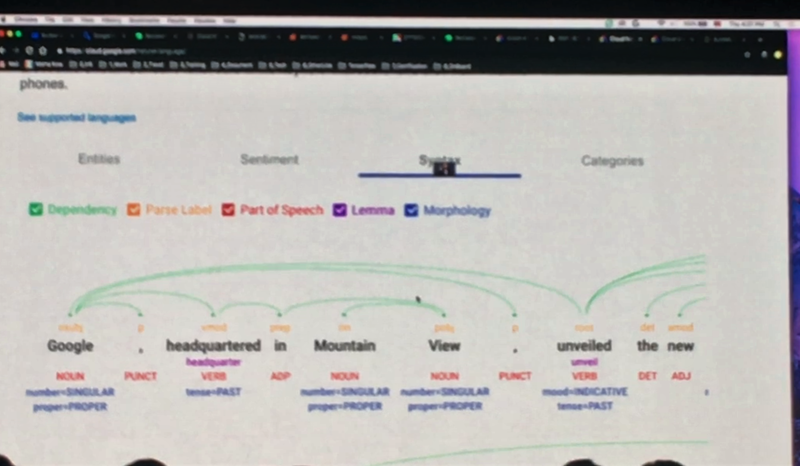
Natural Language API는 문장을 보고 각각의 단어들이 의미하는 것을 분석하여 알려줍니다. 문장의 감정, 문법 분석도 가능하다고 하네요. 이 API를 이용하면 컨퍼런스의 영어 발표 영상을 분석하고 텍스트를 추출하여 그 뜻을 이해할 수 있지 않을까, 그러면 더 이상 영어로 된 영상을 몇번이고 반복해서 보고 들으며 이해하려 노력하지 않아도 되지 않을까(SharedIT INSIGHT 콘텐츠 작성 시간이 좀 단축될 수 있지 않을까)하는 생각이 들더군요. 진짜 가능 하려나요? Youtube에 동영상 올리면 알아서 한글 자막을 딱 달아주는거죠. 지금은 안되는데, 아마 곧 가능해지지 않을까요?(도와줘요 구글느님!! 퇴근 좀 일찍하게 해 주세요 엉엉)
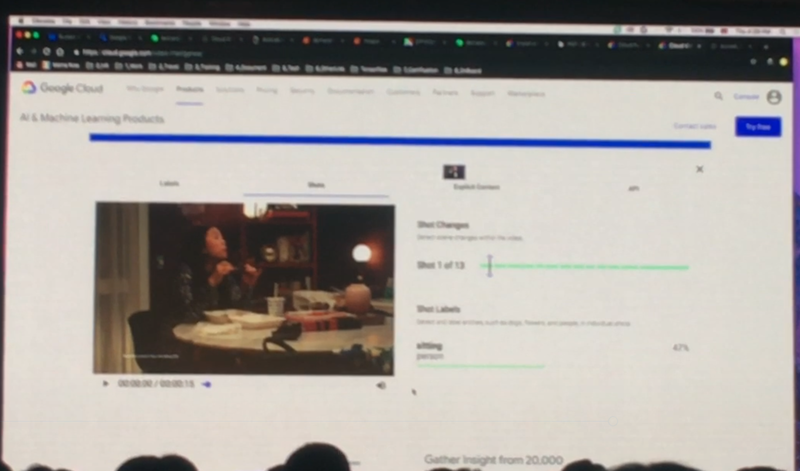
Video Intelligence API는 동영상에서 이미지분석과 같은 기능을 제공합니다. 사람이 일일이 보면서 분석할 수 없는 방대한 양의 포르노그라피도 분석할 수 있다고 합니다. Youtube에 음란물을 올릴 수 없는 것이 이 API의 도움 덕분이지 않을까요?
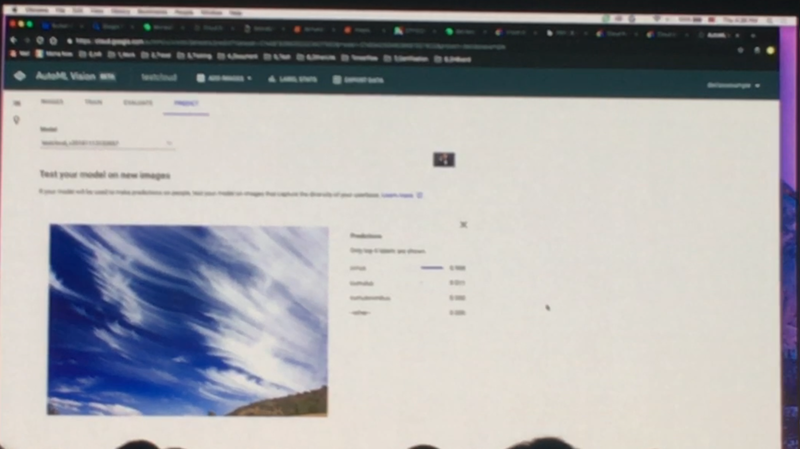
마지막으로 AutoML은 사용자가 머신러닝 모델의 코드를 짜기 어려울 경우 Google Cloud Platform에 학습을 위한 데이터를 업로드하고 학습을 시킨 다음, 그 학습한 머신러닝 모델을 활용해서 분석 및 예측을 하는 것입니다. 구름 사진의 경우 다양한 구름 사진을 업로드한 다음 학습 시키고, 다시 구름 사진을 올려서 분석을 하면 위와 같이 이 구름이 어떤 구름이고 무슨 특징을 가지고 있는 지 결과를 보여주는 것입니다.

이미지를 올리고, 그 이미지가 무엇인지 라벨링(핸드백 사진을 올리고 이게 핸드백인지 적어두는 행위)를 한 뒤 학습시킵니다. 이후 다시 이미지를 올려서 예측을 할 수 있는 것이죠. 이렇게 코드를 모르는 사람도 간편하게 머신러닝을 사용할 수 있습니다.

이것으로 Google Cloud Onboard의 8가지 모듈 정리를 끝냈습니다. 어떠세요? Google Cloud Platform와 Google이 제공하는 다양한 제품, 기술들을 이해하시는 데에 조금은 도움이 되셨기를 바랍니다.
모듈 8까지 진행될 동안 위 사진의 많은 자리가 거의 다 차 있었는데요. 그만큼 Google Cloud에 대한 관심이 많다는 것이겠죠. 저 역시 이번 행사를 통해 클라우드에서 다루는 많은 용어들에 대한 개념을 제대로 이해할 수 있었습니다. 그리고 아직은 갈길이 멀긴 하지만, 구글만큼 머신러닝, AI 분야에 있어서 앞서갈 수 있는 여건이 잘 마련되어 있는 회사가 있을까 싶기도 합니다. 온프레미스 보다 10년은 앞서있다고 하는데, 스카이넷이 진짜 나타날 수 있겠는데요?
어쨌든 기술은 끊임없이 발전합니다. 진짜 스카이넷이 탄생하지 않게 하기 위해서는 지난 Microsoft Future Now에서 다뤄졌었던 AI를 윤리적 차원에서 바라보는 시각, 그리고 법적으로 어떻게 다뤄야 할 것인지에 대한 논의가 활발하게 이루어져야 할 것입니다.
여전히 기술의 진보는 빠르지만 정책은 이를 받쳐주지 못해 지금 이 순간에도 많은 스타트업들의 훌륭한 서비스들이 제대로 운영되지 못하고 있는 것이 현실이니까요. 결국 시간이 해결 해 주겠지만 우리 세대에서 더 나은 미래를 위한 초석을 다지기 위해서라도 AI에 대한 발빠른 각계각층의 논의가 진행되기를 기대 해 보면서 이만 마칩니다. 길고 긴 내용 읽으시느라 고생 많으셨습니다. 끝!
7개의 댓글이 있습니다.
잘 읽었습니다.
Reply내용이 길어서 읽다가 중단하기를 여러번 반복하다 이제야 다 읽었습니다~ ^^;;
중간 중간 충분히 이해 못한 부분도 있고, 고개를 끄덕이며 읽기도 했습니다.
긴 내용 적으시느라 고생 많으셨습니다.
글 중에 스위치(허브)가 들어가야 할 부분에 라우터를 적은게 아닌가 하는 부분이 있어 다시 한번 검토해 보셔야 하지 않을까 하는 생각이 듭니다.
LAN 내에서 컴퓨터들 간에 네트워크 연결을 시켜 주는 역할을 하는 장비는 허브(스위칭)이고, LAN과 LAN을 연결 시켜 주는 역할을 하는 장비가 라우터인데... LAN에 대한 설명을 하시면서 라우터를 잘못 지칭하신게 아닌가 하는 생각이 드네요~
지적 감사합니다. 다시 한번 현장 영상을 확인 해 보니 말씀하신 허브 또는 스위치라는 표현은 쓰지 않고 라우터라고만 표현했습니다. 자료를 찾아보니 라우터가 아닌 허브 또는 스위치가 하는 역할이 맞네요. 스위치로 컴퓨터들을 연결해 네트워크를 구성하고, 이 네트워크들을 연결하는 역할을 라우터가 하는 것이니, 이미지의 라우터와 컴퓨터 사이에 스위치가 있는 것이 맞아 보입니다.
Reply댓글 남기기
댓글을 남기기 위해서는 로그인이 필요합니다.
로그인 회원가입클라우드에 대한 공부가 되었네요
Reply감사합니다~기술이 발전할수록 배울께 넘 많아져요ㅜ
댓글 남기기
댓글을 남기기 위해서는 로그인이 필요합니다.
로그인 회원가입구글의 제품들에 대해 잘 정리해주셔서 감사합니다.
Reply댓글 남기기
댓글을 남기기 위해서는 로그인이 필요합니다.
로그인 회원가입좋은정리 감사합니다.
Reply댓글 남기기
댓글을 남기기 위해서는 로그인이 필요합니다.
로그인 회원가입우와~이번에도 방대한 내용입니다 킵하고 시간날때 천천히 공부할께요
Reply댓글 남기기
댓글을 남기기 위해서는 로그인이 필요합니다.
로그인 회원가입언젠가는 가고싶은 방향입니다... 언젠가는..ㅠ.ㅠ
Reply좋은정보 감사합니다.
댓글 남기기
댓글을 남기기 위해서는 로그인이 필요합니다.
로그인 회원가입